RAG 파이프라인 구축: LLM 환각 현상 해결
RAG 파이프라인 구축: LLM 환각 현상 해결
왜 RAG까지 갔나
PNU x Upstage DOCUMENT AI CHALLENGE에서 해외 파견 의료진을 돕는 챗봇 서비스 똑똑(DocDoc)을 만들었다. 목표는 질문을 받으면 관련 문서를 근거로 답을 만들어 주는 것이었다.
초기 구현은 LLM에 질문만 전달하는 방식이었고, 아래 문제가 있었다.
- 그럴듯한데 근거가 없는 문장이 섞인다
- 없던 내용을 있는 것처럼 말하거나, 출처를 흐리게 말한다
- 특히 의료/논문 컨텍스트에선 그럴듯함이 오히려 리스크가 될 수 있다 이 서비스는 의료 조언 도구가 아니라 문서 탐색 보조로 방향을 잡았다
해결 방향: RAG
핵심은 모델이 근거 없이 단정하지 않게 만드는 것이었다. 그래서 답변 생성 전에 관련 문서 조각을 먼저 찾아서 컨텍스트로 붙이는 RAG(Retrieval-Augmented Generation) 구조로 바꿨다.
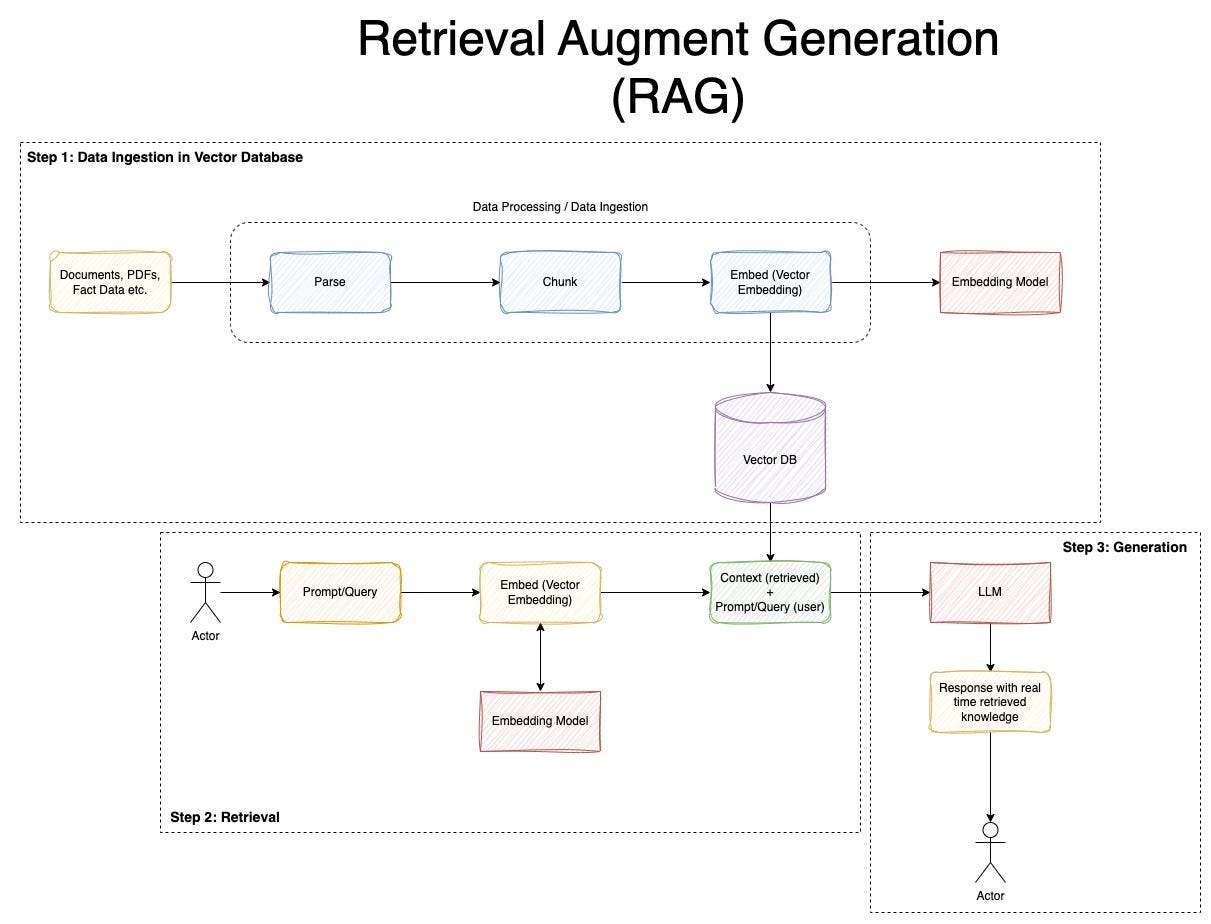
구현은 아래 흐름으로 갔다.
- 사용자 질문을 임베딩 벡터로 변환
- Vector DB(Pinecone)에서 유사한 문서 조각 검색
- 검색 결과(컨텍스트)를 LLM 프롬프트에 포함
- LLM은 컨텍스트 범위 안에서 답변 생성 + 근거를 같이 보여주기
이 구조로 바꾸고 나서, 근거가 불명확한 답변을 줄이고 답변의 근거를 함께 제시할 수 있었다. 완전히 차단하긴 어렵지만, 사용자 입장에서는 답변 출처를 같이 확인할 수 있는 형태가 됐다.
기술 스택(그때 기준)
- Vector DB: Pinecone
- Embedding: Upstage Embeddings
- LLM: Upstage Solar Pro 2
- Framework: LangChain
- Backend: Node.js, Express
SSE 스트리밍으로 화면 반응 개선
RAG를 붙이면 답변이 더 느려진다(검색 + 생성). 로딩만 보여주면 처리 상태를 알기 어렵다.
그래서 응답을 한 번에 보내지 않고, Server-Sent Events(SSE)로 토큰이 생성되는 대로 흘려보내는 방식으로 바꿨다.
- 결과적으로 사용자는 생성 과정을 확인할 수 있고, 화면이 멈춘 것처럼 보이는 문제를 줄일 수 있다
마무리
이 경험을 통해, LLM 문제는 모델만 교체해서 해결하기보다 시스템 설계(근거, 검증, 표현)로 줄여야 하는 경우가 많다는 점을 정리할 수 있었다. RAG는 그 출발점으로 적절했다.
프로젝트: PNU x Upstage DOCUMENT AI CHALLENGE 2025 본선(똑똑, DocDoc) 관련 링크
- GitHub: Neibce/DAIC-docdoc
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.